I've laughed way harder than I should at this.
To all the folks out there who've ever attempted to play with Terraform, OpenTelemetry, Kubernetes, CI/CD pipelines, AWS, Azure, GCP, and the rest: go give the poor soul (whether you call them an SRE, Sysadmin, Network Specialist, Cloud Specialist, Infrastructure Errand Person, BOFH, or whatever) keeping it all running a hug.
They deserve it! For putting up with you. And all the YAML. And HCL.
https://youtu.be/rXPpkzdS-q4
#devstr #devops #memestr
GA Nostr.
Thought of the day: Nostr is an endless hacking fest for someone like me. The rabbit hole is almost bottomless. My last couple of months went like this:
- Haven needs to support Blossom mirroring on Primal mobile? OK, looks like this is a problem in Khatru. Let’s fix that.
- Actually, every Blossom server is doing something slightly different when mirroring, and I don’t want Haven or Khatru to rely on if conditions just to work with different Blossom servers. OK, let’s try to improve the specs.
- Great. Now I need a Blossom client I can quickly hack on to test my changes... Let’s add mirroring support to nak (I haven’t contributed it upstream yet... It's on my to-do list).
- OK, now I’ve got a proper Blossom client to hack on, but nak isn’t playing well with Amber. Let’s figure that one out...
- While we’re at it, since nak has its own bunker, why not add QR code and Nostr Connect token support? I mean, QR code support in the terminal, how cool would that be? Maybe I can pester fiatjaf about implementing persistent profiles too.
- So, in order to contribute I need to contribute some of these changes I need to get acquainted with nip34... ngit and gitworkshop.dev to the rescue.
- Now nak is working great, but for some reason Bunklay and `relay.nsec.app` still aren't playing well with Amber for me. Let’s look into that and experiment with other relays + remote signing software.
Wait… what was I doing again?
And that’s how I end up actively working on Haven while you folks don’t see commits for months. Nostr development is full of distractions. The good kind of distractions!
Thanks for your patience nostr:nprofile1qqszv6q4uryjzr06xfxxew34wwc5hmjfmfpqn229d72gfegsdn2q3fgpzfmhxue69uhkummnw3e82efwvdhk6tcpz4mhxue69uhhyetvv9ujuerpd46hxtnfduhszythwden5te0dehhxarj9emkjmn99urf278z, nostr:nprofile1qqsrhuxx8l9ex335q7he0f09aej04zpazpl0ne2cgukyawd24mayt8gprfmhxue69uhhq7tjv9kkjepwve5kzar2v9nzucm0d5hszxmhwden5te0wfjkccte9emk2um5v4exucn5vvhxxmmd9us2xuyp, nostr:nprofile1qqs827g8dkd07zjvlhh60csytujgd3l9mz7x807xk3fewge7rwlukxgpz9mhxue69uhkummnw3ezumrpdejz772u5wm and nostr:nprofile1qqs06gywary09qmcp2249ztwfq3ue8wxhl2yyp3c39thzp55plvj0sgpzpmhxue69uhkummnw3ezumrpdejqzyrhwden5te0dehhxarj9emkjmn9qydhwumn8ghj7argv4nx7un9wd6zumn0wd68yvfwvdhk6tc7xx9t4 who I’ve been pestering incessantly with all sorts of dumb questions and issues.
Hopefully all this yak shaving is pushing the Nostr ecosystem forward, even if just a bit. Let’s see how far we can take this! More yak shaving to come.
#gm #nostr #devstr #blossom #bud04 #mirroring #nip46 #remoteSigning #nip34 #gitStuff
GA Nostr.
Thought of the day: Nostr is an endless hacking fest for someone like me. The rabbit hole is almost bottomless. My last couple of months went like this:
- Haven needs to support Blossom mirroring on Primal mobile? OK, looks like this is a problem in Khatru. Let’s fix that.
- Actually, every Blossom server is doing something slightly different when mirroring, and I don’t want Haven or Khatru to rely on if conditions just to work with different Blossom servers. OK, let’s try to improve the specs.
- Great. Now I need a Blossom client I can quickly hack on to test my changes... Let’s add mirroring support to nak (I haven’t contributed it upstream yet... It's on my to-do list).
- OK, now I’ve got a proper Blossom client to hack on, but nak isn’t playing well with Amber. Let’s figure that one out...
- While we’re at it, since nak has its own bunker, why not add QR code and Nostr Connect token support? I mean, QR code support in the terminal, how cool would that be? Maybe I can pester fiatjaf about implementing persistent profiles too.
- So, in order to contribute I need to contribute some of these changes I need to get acquainted with nip34... ngit and gitworkshop.dev to the rescue.
- Now nak is working great, but for some reason Bunklay and `relay.nsec.app` still aren't playing well with Amber for me. Let’s look into that and experiment with other relays + remote signing software.
Wait… what was I doing again?
And that’s how I end up actively working on Haven while you folks don’t see commits for months. Nostr development is full of distractions. The good kind of distractions!
Thanks for your patience nostr:nprofile1qqszv6q4uryjzr06xfxxew34wwc5hmjfmfpqn229d72gfegsdn2q3fgpzfmhxue69uhkummnw3e82efwvdhk6tcpz4mhxue69uhhyetvv9ujuerpd46hxtnfduhszythwden5te0dehhxarj9emkjmn99urf278z, nostr:nprofile1qqsrhuxx8l9ex335q7he0f09aej04zpazpl0ne2cgukyawd24mayt8gprfmhxue69uhhq7tjv9kkjepwve5kzar2v9nzucm0d5hszxmhwden5te0wfjkccte9emk2um5v4exucn5vvhxxmmd9us2xuyp, nostr:nprofile1qqs827g8dkd07zjvlhh60csytujgd3l9mz7x807xk3fewge7rwlukxgpz9mhxue69uhkummnw3ezumrpdejz772u5wm and nostr:nprofile1qqs06gywary09qmcp2249ztwfq3ue8wxhl2yyp3c39thzp55plvj0sgpzpmhxue69uhkummnw3ezumrpdejqzyrhwden5te0dehhxarj9emkjmn9qydhwumn8ghj7argv4nx7un9wd6zumn0wd68yvfwvdhk6tc7xx9t4 who I’ve been pestering incessantly with all sorts of dumb questions and issues.
Hopefully all this yak shaving is pushing the Nostr ecosystem forward, even if just a bit. Let’s see how far we can take this! More yak shaving to come.
#gm #nostr #devstr #blossom #bud04 #mirroring #nip46 #remoteSigning #nip34 #gitStuff
QR code support for nak has been merged (thanks, nostr:nprofile1qythwumn8ghj76twvfhhstnjv4kxz7tn9ekxzmnyqyvhwumn8ghj7urewfsk66ty9enxjct5dfskvtnrdakszxnhwden5te0wfjkccte9emk2um5v4exucn5vvhxxmmdqqsrhuxx8l9ex335q7he0f09aej04zpazpl0ne2cgukyawd24mayt8g9gy2m7!).
If anyone else feels like testing `nostrconnect://` / client-side initiated connections, here you go: https://github.com/fiatjaf/nak/pull/73
Just start the bunker, grab the `nostrconnect://` token from your client, type `c`, space, paste the token, and press enter.
So far, I’ve tested it with nak itself, noStrudel, Nosotros, and Coracle. If your favourite NIP-46-enabled client doesn’t work with it, please let me know.
#devstr #nak #cli #nip46 #remoteSigner
GM nostr! Hint of the day for the devs out there: I was heavily reliant on Dependabot to keep my project's software versions up to date (you are keeping your dependencies up to date, right?).
Some colleagues who are deeper into OSS told me to try Renovate, but I mostly dismissed it as just alt tech.
Now that I’m working on some software outside of GitHub, I decided to give it a go. And I have to say: folks were right. Renovate is just... better. It does pretty much everything I need out of the box, and it avoids a lot of manual work or extra CI steps that Dependabot requires.
https://image.nostr.build/0e33d200c612c8c659ce8447c75d4e302402e0c6fff0db9d81a3e4e4389091f6.jpg
Here are some of my favourite features (in no particular order):
- Works much better with monorepos out of the box
- Great (and I mean it) presets
- Has a nice dashboard to track what's going on
- In the JVM ecosystem, it upgrades Gradle and Maven Wrapper versions
- Same for Go, it upgrades the Go version in go.mod
- It can pin versions in ecosystems where that's best practice (including, somewhat Ironically, GitHub Actions)
- Has better confidence metrics and update recommendations compared to Dependabot
- First-party integration with OSV (though you can also use GitHub’s Advisory Database, which, credit where it's due, is a great and convenient resource)
- Requires way less YAML fluff to auto-approve and auto-merge PRs after CI passes (Assuming you do have proper tests and checks running, which you do right? Right???)
And the big one: it works everywhere.
On most platforms Renovate already offers its own Bots and integration tooling, but you can also use the CLI or even run / selfhost your own bot.
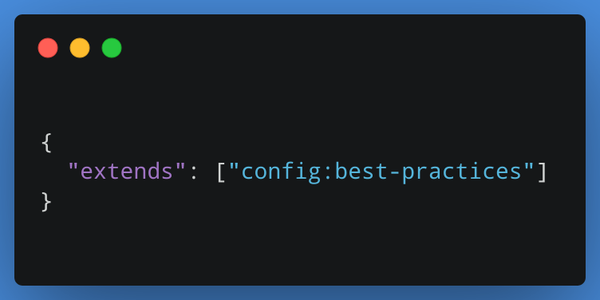
In most cases, all you need to do is install the Renovate bot and drop a renovate.json like the one below into your repo. Then just sit back and watch the magic happen.
https://image.nostr.build/0393229c4b1f0b04048c21522de9b8b5d7d4e6c76a4026d71f5053748ff4bfe6.png
You can customise a gazillion settings to your heart’s content, but unlike GitHub Actions + Dependabot combos, I didn’t need to write loads of config to get it working the way I wantm My go-to renovate.json is just 5 lines of config at the moment.
Definitely worth checking out!
https://www.mend.io/renovate/
#gm #devstr #devops #renovatebot #oss #dependabot #automation #softwaremaintenance #dependencymanagement #ci #buildtools #developerexperience #selfhosted
GM Nostr.
Hint of the day for the devs out there: I was heavily reliant on Dependabot to keep my project's software versions up to date (you are keeping your dependencies up to date, right?).
Some colleagues who are deeper into OSS told me to try Renovate, but I mostly dismissed it as just alt tech.
Now that I’m working on some software outside of GitHub, I decided to give it a go. And I have to say: folks were right. Renovate is just... better. It does pretty much everything I need out of the box, and it avoids a lot of manual work or extra CI steps that Dependabot requires.
Here are some of my favourite features (in no particular order):
- Works much better with monorepos out of the box
- Great (and I mean it) presets
- Has a nice dashboard to track what's going on
- In the JVM ecosystem, it upgrades Gradle and Maven Wrapper versions
- Same for Go, it upgrades the Go version in `go.mod`
- It can pin versions in ecosystems where that's best practice (including, somewhat Ironically, GitHub Actions)
- Has better confidence metrics and update recommendations compared to Dependabot
- First-party integration with OSV (though you can also use GitHub’s Advisory Database, which, credit where it's due, is a great and convenient resource)
- Requires way less YAML fluff to auto-approve and auto-merge PRs after CI passes (assuming you do have proper tests and checks running, right? Right???)
And the big one: it works everywhere.
On most platforms Renovate already offers its own Bots and integration tooling, but you can also use the CLI or even run / selfhost your own bot.
In most cases, all you need to do is install the Renovate bot and drop a `renovate.json` like the one below into your repo. Then just sit back and watch the magic happen.
https://haven.accioly.social/2f06a6afa7b48ebbdf662ff94e8896a511f37e9f71ccf524a1fe1b885a532a80.png
You can customise a gazillion settings to your heart’s content, but unlike GitHub Actions + Dependabot combos, I didn’t need to write loads of config to get it working the way I wantm My go-to `renovate.json` is just 5 lines of config at the moment.
Definitely worth checking out:
https://docs.renovatebot.com/
#gm #devstr #devops #renovatebot #oss #dependabot #automation #softwaremaintenance #ci #monorepo #buildtools #developerexperience #selfhosted

GM Nostr.
Hint of the day for the devs out there: I was heavily reliant on Dependabot to keep my project's software versions up to date (you are keeping your dependencies up to date, right?).
Some colleagues who are deeper into OSS told me to try Renovate, but I mostly dismissed it as just alt tech.
Now that I’m working on some software outside of GitHub, I decided to give it a go. And I have to say: folks were right. Renovate is just... better. It does pretty much everything I need out of the box, and it avoids a lot of manual work or extra CI steps that Dependabot requires.
Here are some of my favourite features (in no particular order):
- Works much better with monorepos out of the box
- Great (and I mean it) presets
- Has a nice dashboard to track what's going on
- In the JVM ecosystem, it upgrades Gradle and Maven Wrapper versions
- Same for Go, it upgrades the Go version in `go.mod`
- It can pin versions in ecosystems where that's best practice (including, somewhat Ironically, GitHub Actions)
- Has better confidence metrics and update recommendations compared to Dependabot
- First-party integration with OSV (though you can also use GitHub’s Advisory Database, which, credit where it's due, is a great and convenient resource)
- Requires way less YAML fluff to auto-approve and auto-merge PRs after CI passes (assuming you do have proper tests and checks running, right? Right???)
And the big one: it works everywhere.
On most platforms Renovate already offers its own Bots and integration tooling, but you can also use the CLI or even run / selfhost your own bot.
In most cases, all you need to do is install the Renovate bot and drop a `renovate.json` like the one below into your repo. Then just sit back and watch the magic happen.
https://haven.accioly.social/2f06a6afa7b48ebbdf662ff94e8896a511f37e9f71ccf524a1fe1b885a532a80.png
You can customise a gazillion settings to your heart’s content, but unlike GitHub Actions + Dependabot combos, I didn’t need to write loads of config to get it working the way I wantm My go-to `renovate.json` is just 5 lines of config at the moment.
Definitely worth checking out:
https://docs.renovatebot.com/
#gm #devstr #devops #renovatebot #oss #dependabot #automation #softwaremaintenance #ci #monorepo #buildtools #developerexperience #selfhosted
Big rant against GitHub of the day.
I finally managed to get "Accibot"'s account reinstated: https://github.com/accibot. It's now merrily updating my Golang repos.
It was flagged about 3 hours after creation for, and I quote, "because you appear to have registered more than a single free user account. The GitHub Terms of Service Account Requirements state that an individual may not maintain more than one account."
Meanwhile, here's what GitHub's ToS actually says:
> - A machine account is an Account set up by an individual human who accepts the Terms on behalf of the Account, provides a valid email address, and is responsible for its actions. A machine account is used exclusively for performing automated tasks. Multiple users may direct the actions of a machine account, but the owner of the Account is ultimately responsible for the machine's actions. You may maintain no more than one free machine account in addition to your free Personal Account.
> - One person or legal entity may maintain no more than one free Account (if you choose to control a machine account as well, that's fine, but it can only be used for running a machine).
By the way, before anyone asks: Renovate can update Golang’s version (Dependabot can only update dependencies). You don’t need to use a bot to do this manually: https://github.com/renovatebot/renovate.
This is all part of an experiment. I want a machine account to be able to generate and sign HAVEN releases, and handle all sorts of CI/CD shenanigans in a portable way, in case we ever decide to move off GitHub.
At the moment, GitHub is a necessary pain in the neck for maintainers. For example, I’m happy to migrate to NIP-34, run my own instance of ngit-relay (can’t thank you enough nostr:nprofile1qyt8wumn8ghj7un9d3shjtnwdaehgu3wvfskueqpp4mhxue69uhkummn9ekx7mqpz3mhxue69uhhyetvv9ujuerpd46hxtnfduq32amnwvaz7tm9v3jkutnwdaehgu3wd3skueqpzpmhxue69uhkummnw3ezuamfdejszgnhwden5te0dpshvetw9ejxzmnrdah8wctev3jhvtnrdakj76twvfhhsqguwaehxw309a5xzan9dchxgctwvdhkuamp09jx2a3wvdhk6qpq5qydau2hjma6ngxkl2cyar74wzyjshvl65za5k5rl69264ar2exskxljkd ), or use non-Nostr tech like Forgejo. Still, this basically means we'll get little to no contributions from the community, even from a tech-savvy crowd like we have here on Nostr.
So yeahp, I keep having to jump through hoops to push my code to GitHub so that Microsoft and OpenAI can use it to train LLMs and build more vibe-based coding tools for you folks.
Suggested Hashtags:
#devstr #GitHub #Rant #MachineAccounts #FOSS #SelfHosting #NIP34
Showing page 1 of
16 pages


